
If you have ever wondered how blockchain systems can verify millions of transactions without requiring every node to store and process massive amounts of data, the answer lies in a compact and powerful cryptographic structure known as the Merkle Tree.
First proposed by Ralph Merkle in 1979 at Stanford University, the Merkle Tree has become a core architectural component of most modern blockchain systems, including Bitcoin and Ethereum.
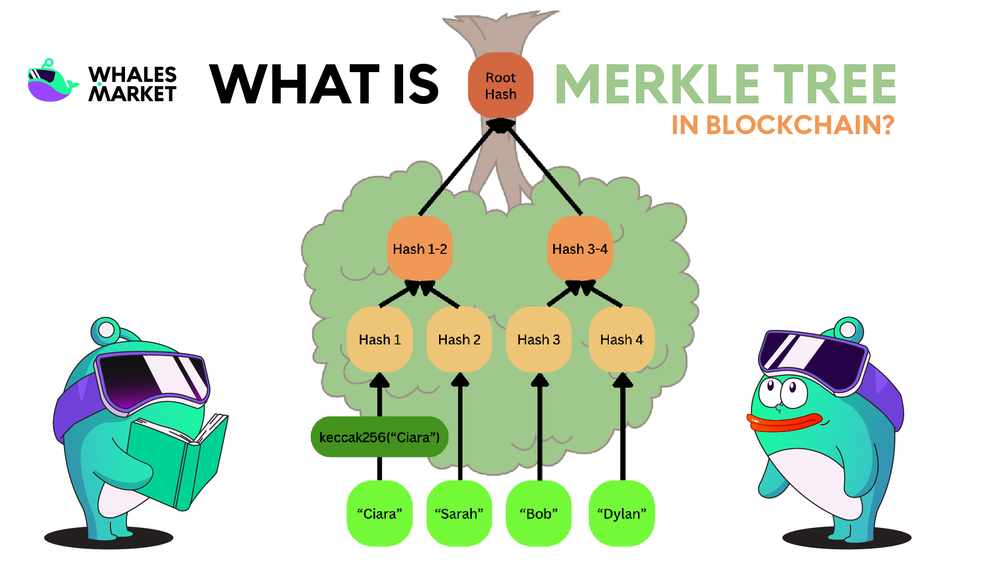
What is the Merkle Tree?
A Merkle Tree is a binary hash-based data structure in which data is organized hierarchically, allowing efficient verification of individual data elements without accessing the entire dataset.
Instead of storing raw data, the tree stores cryptographic hashes. Each piece of data is first hashed, and pairs of hashes are then combined and hashed again, forming higher levels of the tree. This process continues until a single hash remains at the top, representing the entire dataset.
This design enables fast and efficient verification. Rather than checking all data, a user only needs a small set of hashes to confirm that a specific piece of data is included in the tree.
Because cryptographic hash functions are highly sensitive to input changes, even a small modification in the data produces a completely different root hash. This makes Merkle Trees an effective mechanism for detecting data tampering in decentralized systems.
How Does a Merkle Tree Work?
Structure of Merkle Tree in blockchain
This structure consists of three closely connected components:
- Leaf Nodes: These form the lowest level of the tree, where each node represents the hash of the original data. In blockchain systems, this data is typically a transaction.
- Non-Leaf Nodes: These internal nodes are created by combining and hashing two adjacent child nodes.
- Merkle Root: The node at the top of the tree is a single hash representing the entire dataset. Due to the avalanche effect of cryptographic hash functions, even a one-bit change in a leaf node results in a completely different Merkle Root.
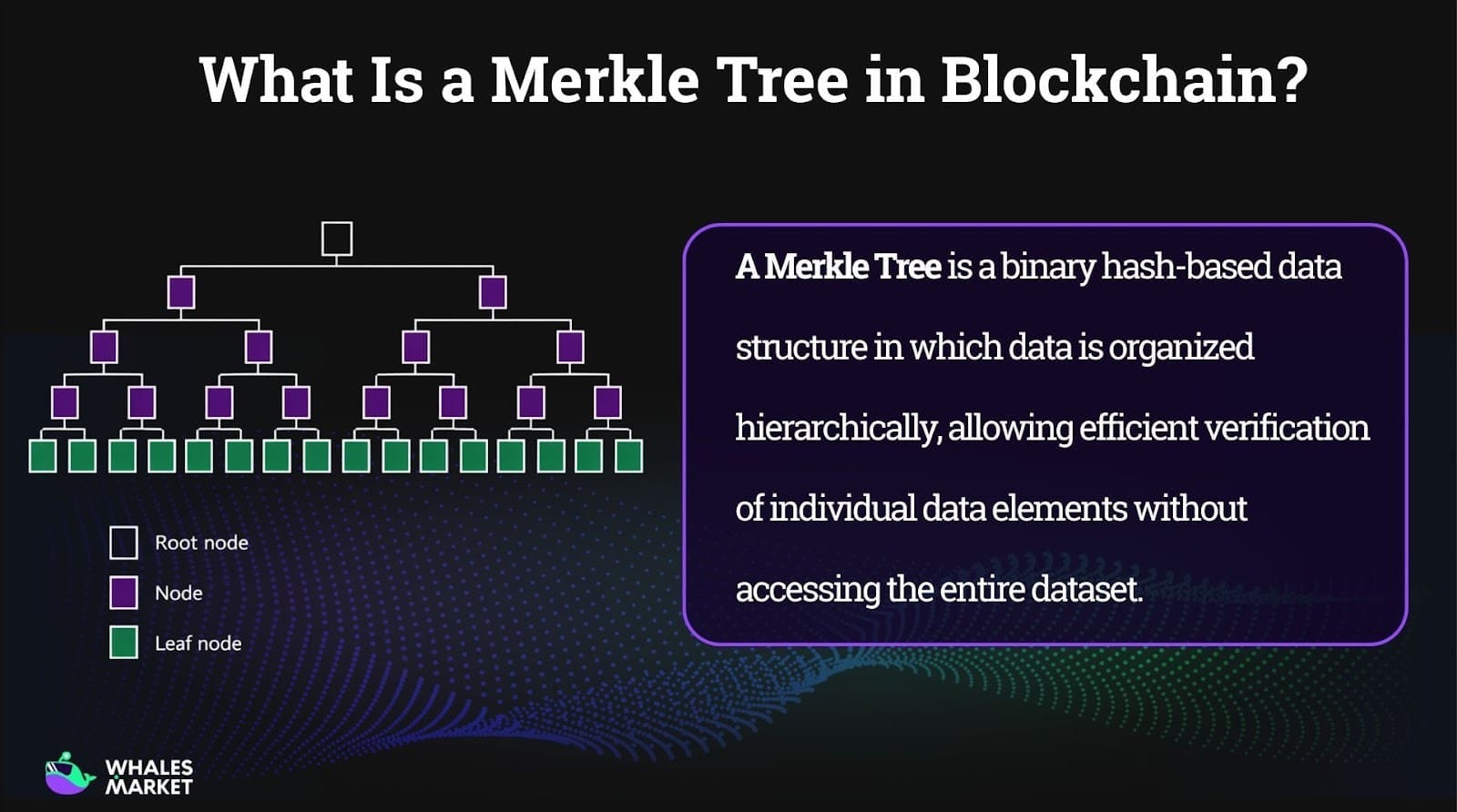
A Merkle Tree operates in two tightly connected phases: tree construction and transaction verification. The attached diagram illustrates both phases within a single structure.
Merkle Tree construction (Bottom-Up)
Step 1: Each transaction in a block, labeled m1, m2, m3, and so on, is independently hashed using a cryptographic hash function. These hashes form the leaf nodes of the tree. Example: m1 is hashed into h1, m2 into h2, m3 into h3, and so on up to m15 into h15.
Step 2: Adjacent hashes are paired, concatenated, and hashed again to create parent nodes. Example: h1 and h2 are combined to form h12, h3 and h4 form h34, h5 and h6 form h56, h7 and h8 form h78.
Step 3: This pairing and hashing process is repeated at each level, with every intermediate node representing a commitment to all data beneath it. Example: h12 and h34 are combined to form h1234, while h56 and h78 form h5678.
Step 4: The process continues until a single hash remains at the top of the tree, known as the Merkle Root. Example: all intermediate hashes are combined step by step to produce the final Merkle Root.
Transaction verification using Merkle Proofs
To verify a specific transaction, such as m6 (highlighted as X in the diagram), a verifier does not need the entire dataset. Instead, only the hash of m6 and the minimal set of sibling hashes along the path to the root are required.
Example path for m6:
- h6 is combined with h5 to form h56
- h56 is combined with h78 to form h5678
- h5678 is combined with higher-level hashes until the Merkle Root is reached
This allows the verifier to reconstruct the path and confirm that m6 is included in the tree, without needing access to all other transactions.
Primary use of a Merkle Tree
Why Merkle Tree is used in Blockchain
To understand the importance of Merkle Trees, it is necessary to consider how blockchain systems operate. A blockchain is a distributed database with no central server, where every node must independently verify data integrity.
Merkle Trees address three fundamental challenges simultaneously:
- Blockchain systems cannot rely on trust, so all data must be independently verifiable.
- Data size grows rapidly over time, making full block downloads and verification impractical for resource-constrained devices.
- Users and nodes often need to verify a specific transaction rather than an entire transaction set.
Core benefits of Blockchain Merkle Trees
Through their hierarchical hash-based design, Merkle Trees deliver several transformative benefits to blockchain architecture:
- Efficient verification: Light clients only need to download the block header, approximately 80 bytes, along with a compact Merkle Proof rather than the full block. Verification complexity is reduced from O(n) to O(log n).
- Data integrity: The Merkle Root functions as a cryptographic commitment. Any unauthorized change in the data is immediately detected through a mismatch at the root level.
- Resource optimization: Reduced storage and bandwidth requirements allow blockchain networks to scale to millions of users without requiring specialized hardware.
- Simplified synchronization: Nodes can compare Merkle Roots to detect inconsistencies instead of exchanging complete transaction datasets.
Verkle tree vs. Merkle tree: What is the difference?
Both Verkle trees and Merkle trees are cryptographic data structures designed to efficiently verify large datasets. While they share the same goal, ensuring data integrity without requiring full data access, they differ significantly in how they scale and handle proof generation.
- A Merkle tree organizes data in a binary hash structure, where each parent is derived from two child nodes. This allows efficient data verification, but proof sizes grow as the dataset increases, making it less efficient for large-scale state.
- A Verkle tree replaces hash-based branching with vector commitments, enabling a much higher branching factor. This results in significantly smaller proofs, making it more efficient for large datasets.
| Feature | Merkle Tree | Verkle Tree |
|---|---|---|
| Core mechanism | Hash-based structure | Vector commitments (polynomial commitments) |
| Tree structure | Binary (2 children per node) | High branching (e.g., 256 children per node) |
| Proof size | Grows logarithmically with data | Much smaller, near constant-size |
| Scalability | Less efficient for large datasets | Optimized for large-scale state |
| Verification cost | Low and efficient | Higher due to complex cryptography |
| Storage requirement | Requires more state data | Enables stateless clients |
| Complexity | Simple, widely used | More complex, newer technology |
| Security | Based on hash functions | Depends on vector commitment assumptions |
| Quantum resistance | Strong (hash-based) | Potential concerns depending on scheme |
| Current usage | Bitcoin, Ethereum (current), most blockchains | Ethereum future upgrades, next-gen blockchains |
| Main advantage | Simple and reliable | Smaller proofs, better scalability |
| Main drawback | Larger proofs at scale | Higher complexity and computation cost |
In summary, Merkle trees prioritize simplicity and proven reliability, while Verkle trees focus on reducing proof size and improving scalability.
As blockchain systems evolve, Verkle trees are increasingly seen as a potential upgrade for handling large and complex state data more efficiently.
Practical Applications and Representative Case Studies
Beyond organizing transactions within blocks, Merkle Trees serve as a foundation for advanced verification and scalability mechanisms both within and outside the blockchain ecosystem.
Bitcoin, SPV, and the Lightning Network
In the original design of Bitcoin, Merkle Trees are used to support Simplified Payment Verification (SPV), allowing light clients to verify transactions using only block headers and Merkle Proofs. This mechanism enabled Bitcoin usage on resource-constrained devices such as mobile wallets.
As Bitcoin adoption expanded to daily payments, SPV alone proved insufficient to meet throughput and latency requirements. This limitation led to the development of the Lightning Network, a Layer 2 solution designed to process transactions off-chain.
Within the Lightning Network, Merkle-based data structures are used to manage and verify the state of payment channels. Each channel can be viewed as an off-chain state set, where the Merkle Root serves as a cryptographic commitment to the current state.
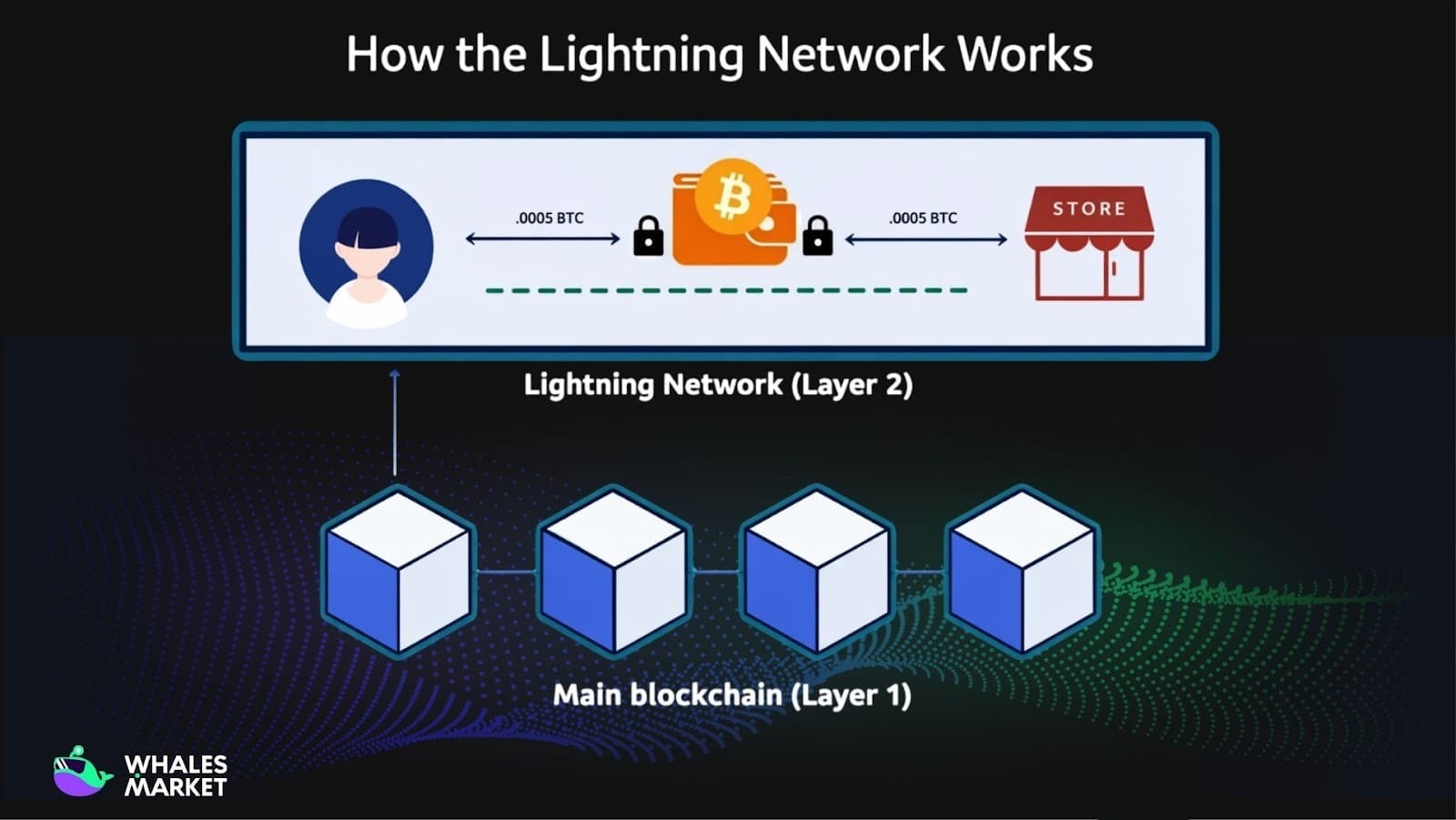
In the event of a dispute, participants only need to provide the relevant Merkle Proof rather than the entire transaction history, enabling fast and efficient resolution.
A notable case study is Lightspark, a Lightning infrastructure platform widely adopted since 2023. Lightspark applies Merkle Tree-based mechanisms to process millions of near-instant transactions, significantly reducing transaction fees and expanding Bitcoin usability for micropayments and retail scenarios.
Ethereum, Merkle Patricia Trie, Verkle Trees, and ZK-Rollups
While Bitcoin focuses primarily on transactions, Ethereum applies Merkle Trees at a broader scale to manage the entire system state. Ethereum implements the Merkle Patricia Trie to store account state, contract code, and storage, with each block updating a set of Merkle Roots representing the global state.
As Ethereum moves toward long-term goals such as stateless clients and sharding, the Merkle Patricia Trie reveals limitations in proof size and efficiency. For this reason, Ethereum began transitioning toward Verkle Trees in 2024, a structure combining Merkle Trees with vector commitments.
Verkle Trees significantly reduce proof size, enabling nodes to verify block validity without storing the full state. This capability is considered critical for Ethereum 2.0 and subsequent scalability upgrades.
Read more: What is Fusaka Upgrade? Ethereum’s Next Major Hard Fork
In parallel, Merkle-based structures play a central role in ZK-Rollup solutions. In systems such as Polygon zkEVM and zkSync Era, Merkle Trees are used to commit off-chain state transitions, while zero-knowledge proofs ensure the correctness of those changes.
As a result, thousands of transactions per second can be processed off-chain, while on-chain verification remains computationally efficient. Since 2023, zkSync Era has demonstrated that this model can reduce DeFi costs by more than 100% compared to Ethereum mainnet.
Applications Beyond Blockchain: From Enterprise to IoT and Internet Infrastructure
Outside the cryptocurrency domain, Merkle Trees continue to demonstrate value as a general-purpose cryptographic primitive across large-scale distributed systems.
- Enterprise blockchain (Hyperledger Fabric): In enterprise blockchain systems such as Hyperledger Fabric, Merkle Trees are used to manage access control and verify data integrity across organizations. Since 2023, IBM and logistics partners such as Maersk have applied Fabric in supply chain traceability, where Merkle Roots ensure data immutability while protecting sensitive information.
- IoT and Large-scale distributed systems: In the Internet of Things domain, platforms such as IOTA use DAG-based structures incorporating Merkle-derived elements to verify data from millions of devices without requiring a full chain. One example is the BLAST-IoT project in 2023, where Merkle-based proofs enable low-overhead verification of sensor data in smart city environments.
- Content Distribution Networks (CDNs): Since 2024, modern CDNs such as Cloudflare have integrated Merkle Tree-based mechanisms to support content integrity verification in distributed and peer-to-peer models.
- Proof of Solvency Updates: Following the collapse of FTX, Proof of Solvency has become a new transparency standard for cryptocurrency exchanges. By 2026, major exchanges such as Coinbase have combined Merkle Trees with zk-STARKs to provide periodic reserve reports, improving financial transparency while enhancing user privacy under increasingly strict regulations such as MiCA in the European Union.
Conclusion
Through hierarchical hashing, Merkle Tree enables efficient, trustless data verification with minimal storage, bandwidth, and computation.
From Bitcoin and Ethereum to Layer 2 networks, ZK-Rollups, and enterprise systems, Merkle Trees have proven their flexibility and longevity. As blockchain systems move toward stateless clients, rollups, and privacy-preserving proofs, Merkle-based designs and successors like Verkle Trees will remain central to decentralized architectures.
FAQs
Q1. What problem does a Merkle Tree solve in blockchain?
A Merkle Tree enables efficient and trustless verification of data by allowing nodes to confirm the inclusion of a transaction without downloading or processing the entire dataset.
Q2. Is a Merkle Tree required for all blockchains?
While not strictly required, most modern blockchains rely on Merkle Trees or Merkle-based structures because they provide scalability, data integrity, and efficient verification.
Q3. How does a Merkle Tree improve blockchain scalability?
By reducing verification complexity from O(n) to O(log n), Merkle Trees allow light clients and Layer 2 solutions to operate with minimal data and computation.
Q4. Are Merkle Trees only used for transactions?
No. In blockchains like Ethereum, Merkle-based structures are also used to manage global state, smart contract storage, and off-chain state commitments.
Q5. What is the difference between a Merkle Tree and a Merkle Proof?
A Merkle Tree is the full data structure, while a Merkle Proof is a minimal set of hashes used to verify that a specific piece of data belongs to that tree.
Q6. Will Merkle Trees be replaced in the future?
Rather than being replaced, Merkle Trees are being extended through designs such as Verkle Trees, which aim to reduce proof size and support next-generation blockchain scalability.